Sending Kafka topics events to HTTP endpoints
My experience with streaming data so far has been for internal use, streaming data within the same infrastructure. I wanted to try out the HTTP sink connector to see how sending data out to external endpoints might work.
I created a small project to source data from a relational database using Debezium to populate some kafka topics and then added the HTTP connector to send data from one of the topics to a HTTP endpoint.
It works well and had a couple of pleasant surprises such as the connector auto creates topics in the kafka cluster to store a record of errors and successes of the HTTP calls. That’s great for debugging and delivery issues. You can control the topic names in the connector config too.
I created a docker compose file that creates a Mariadb Database with a tiny products table and a Debezium container. The first connector is added to source the data from the database and populate kafka topics. The second connector is the HTTP connector, to send events form one of the topics to a HTTP endpoint.
I used Warpstream as my kafka cluster and I used Ngrok as a temporary endpoint to send data to so I could inspect the data that is received.
The source connector to read data from a table in the database is located at files/connector_mariadb.json looks like the following, it is a minimal connector, no serialization of the data:
{
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"database.history.kafka.bootstrap.servers": "api-xxxxxxxxxx.warpstream.com:9092",
"database.history.kafka.topic": "history",
"database.hostname": "mariadb",
"database.password": "rootpassword",
"database.port": "3306",
"database.server.id": "12",
"database.server.name": "myconnector",
"database.user": "root",
"database.whitelist": "mydatabase",
"schema.history.internal.kafka.bootstrap.servers": "api-xxxxxxxxxx.warpstream.com:9092",
"schema.history.internal.kafka.topic": "schema-changes.mydatabase",
"table.whitelist": "mydatabase.products",
"tasks.max": "1",
"topic.prefix": "testing",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState",
"transforms": "unwrap"
}
The fields to pay attention to in the JSON config are:
database.history.kafka.bootstrap.servers&schema.history.internal.kafka.bootstrap.servers- your kafka brokers, in my case Im using WarpStreamdatabase.*fields - to specify the connection details to the databasetable.whitelist- the table you want to pull data from, written in the format of schema.tablename
Debezium will create a number of topics in the kafka cluster, in this case it will create a topic called testing.mydatabase.products bases on the prefix and table.whitelist contents.
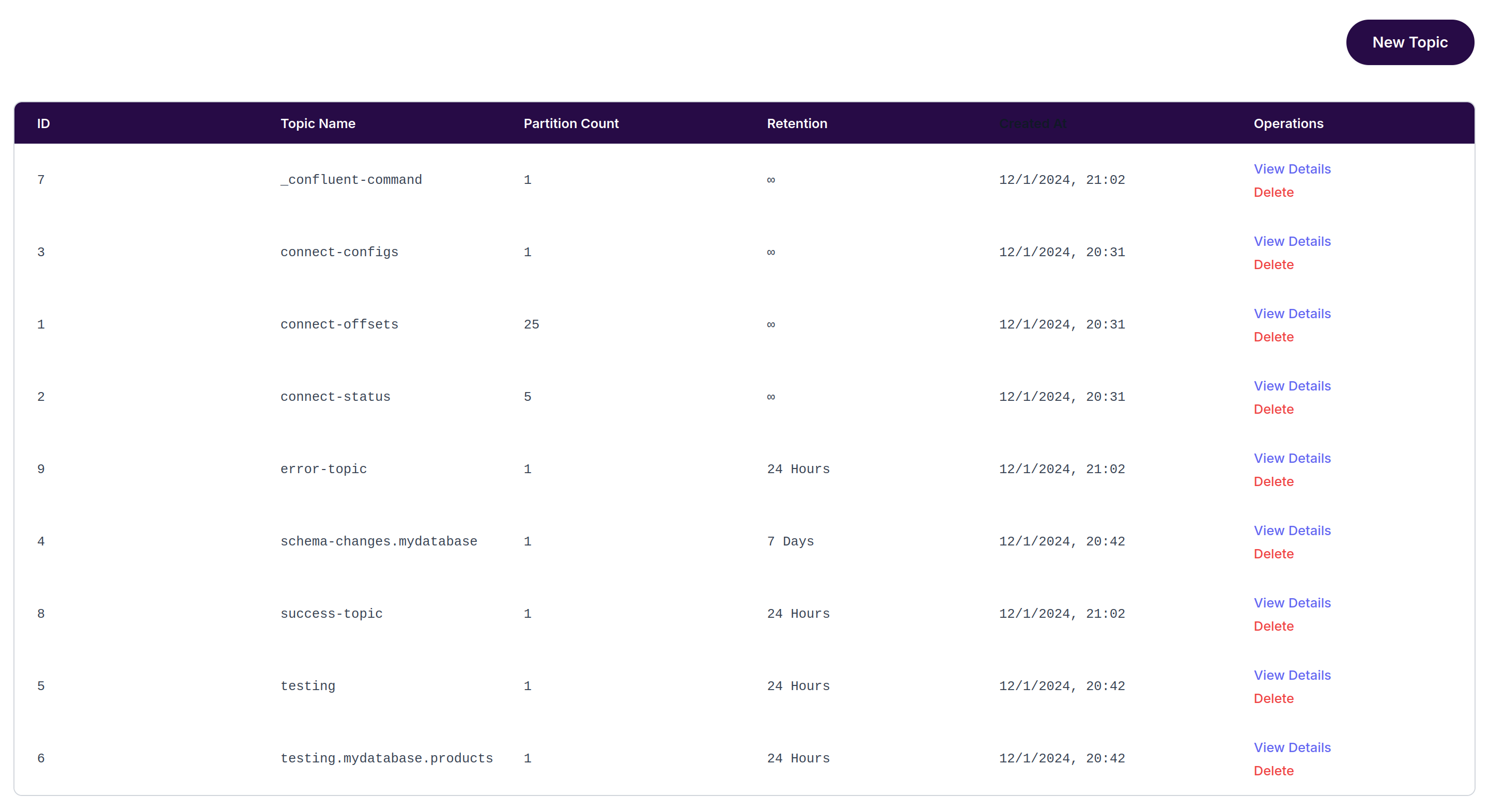
Once the topic is in place with some records, I can then add the HTTP sink connector, located at files/connector_http.json. The connector config looks like the following:
{
"connector.class": "io.confluent.connect.http.HttpSinkConnector",
"tasks.max": "1",
"topics": "testing.mydatabase.products",
"http.api.url": "https://xxxxxxxxxx.ngrok-free.app",
"request.method": "POST",
"headers": "Content-Type:application/json",
"batch.size": "3",
"max.retries": "3",
"retry.backoff.ms": "3000",
"connection.timeout.ms": "2000",
"request.timeout.ms": "5000",
"confluent.topic.bootstrap.servers": "api-xxxxxxxxxx.warpstream.com:9092",
"reporter.bootstrap.servers": "api-xxxxxxxxxx.warpstream.com:9092",
"reporter.error.topic.name": "error-topic",
"reporter.error.topic.replication.factor": "1",
"reporter.result.topic.name": "success-topic",
"reporter.result.topic.replication.factor": "1"
}
The fields to pay attention to in the JSON config are:
topics- thats the topic in kafka you want to respond to, in my case its ‘products’http.api.url- thats the URL to send the events to, in my case is an ngrok endpoint for testingconfluent.topic.bootstrap.servers&reporter.bootstrap.servers- your kafka brokers, in my case Im using WarpStream
For an API endpoint I used ngrok, I started it locally using the following command and it gave me a URL to add to my HTTP connector
ngrok http 80
Once the connectors are updated with any changes you want to make you can start the containers.
Run docker-compose up -d and connect to the Debezium container:
docker exec -it debezium /bin/bash
Docker compose will upload the connectors in to the Debezium container, you can start the connectors using to following commands:
Create the source connector:
curl -X PUT http://localhost:8083/connectors/my_database/config -H "Content-Type: application/json" -d @connector_mariadb.json
Give it a moment to create the topics and then create the HTTP sink connector:
curl -X PUT http://localhost:8083/connectors/http/config -H "Content-Type: application/json" -d @connector_http.json
You should see at least 3 calls to the API endpoint, one for each of the 3 records thats in the database by default. Adding or updating records in the table will trigger more calls to the endpoint.
The events look like the following in Ngrok
Struct{id=3,name=Product C,price=39.99}
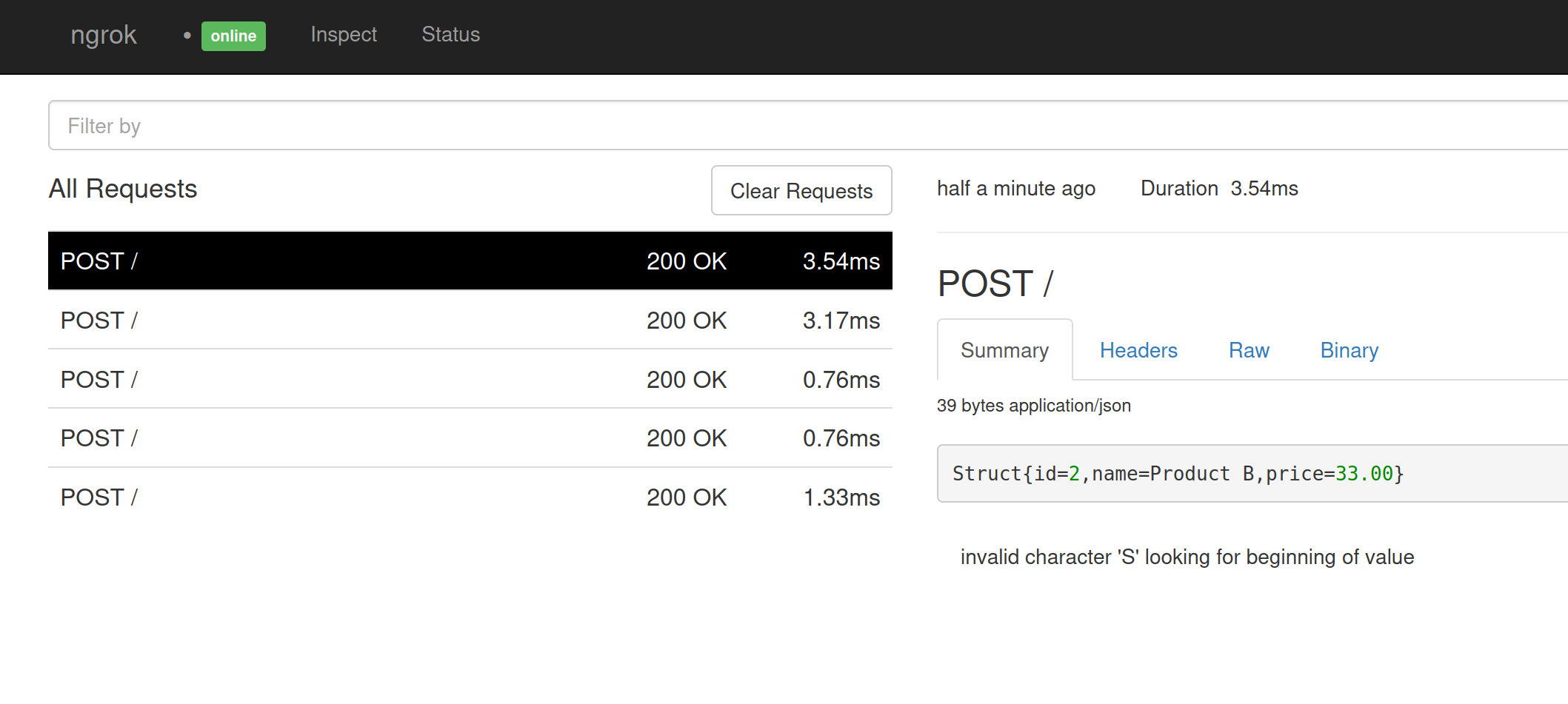
It doesn’t trigger a HTTP event for any schema changes, but any events after a schema change will contain the data for any new columns that are added. I added a notes column and the data appeared in the next HTTP call without any changes.
Struct{id=5,name=product E,price=33.00,notes=great product}
Schema changes are recorded in another topic called schema-changes.mydatabase so another HTTP sink could be used to monitor that topic if you wanted to watch for schema changes.
Overall a quick and successful test, Ill be able to use this connector in future to send content form topics off to API endpoints, handy for keeping systems in sync.
The files I used for this are available here in Github: https://github.com/gordonmurray/debezium_warpstream_http_sink