Apache Flink and Apache Iceberg
I recently tried out using Flink with Apache Paimon. Paimon is a “Streaming data lake platform with high-speed data ingestion”. My hope is to find a convenient way for Flink to send data to s3 for longer term storage in a format that I can query easily again if need to down the line.
Paimon was straight forward to get up and running within Flink and it stored data in s3 in ORC format. ORC is not a format I’ve worked with before so I wasn’t too excited by it and unfortunately I didn’t see a option to change the format.
After trying Paimon, I was reminded of Apache Iceberg. Paimon is still in the Incubating stage at Apache and Iceberg graduated from the Incubator in 2020 so Iceberg might have been a more mature solution for me to try out first.
Having tried Iceberg, the data that it produces in an s3 bucket after CDCing from a test database seems more usable to me compared to the ORC Files produced by Paimon. The data is stored in parquet format and its snapshots are stored in Avro format, which I have some experience with. It has added metadata files too in json format.
The folder structure it creates on s3 is below. Its a folder structure with the name of the database and a folder per table. Inside each “table” is a data folder with the parquet files and a “metadata” folder with snapshots in avro format.
my-test-bucket/iceberg/
└── my_database
└── my_products
├── data
│ └── 00000-0-97c48300-6a94-485e-ae0d-d103aec5731f-00001.parquet
└── metadata
├── 8bf311cc-aa78-4fe3-b6ce-c8c1191c9591-m0.avro
├── snap-818359114004327704-1-681279e0-1f89-428e-8ca4-350082edd535.avro
├── v22.metadata.json
└── version-hint.text
I was able to insert more records in to the test database and Flink picked up on the changes. The new records added to the Iceberg data in s3 without issue.
When I altered the table to add a new column however I didn’t see that reflected in the data in s3. The newer metadata files created after adding a column still show a structure with the 3 original fields in it and not 4 as expected. So theres more to learn there.
Even though Im working with only a dozen records or so for testing, the Sink task in the Flink job continued to be busy after sending all the data, which is a bit concerning for such as small number of records. Though it could be the checkpointing as I had that set to checkpoint everey 10 seconds which is a bit much and adds a bit of overhead to its workload as far as I know.
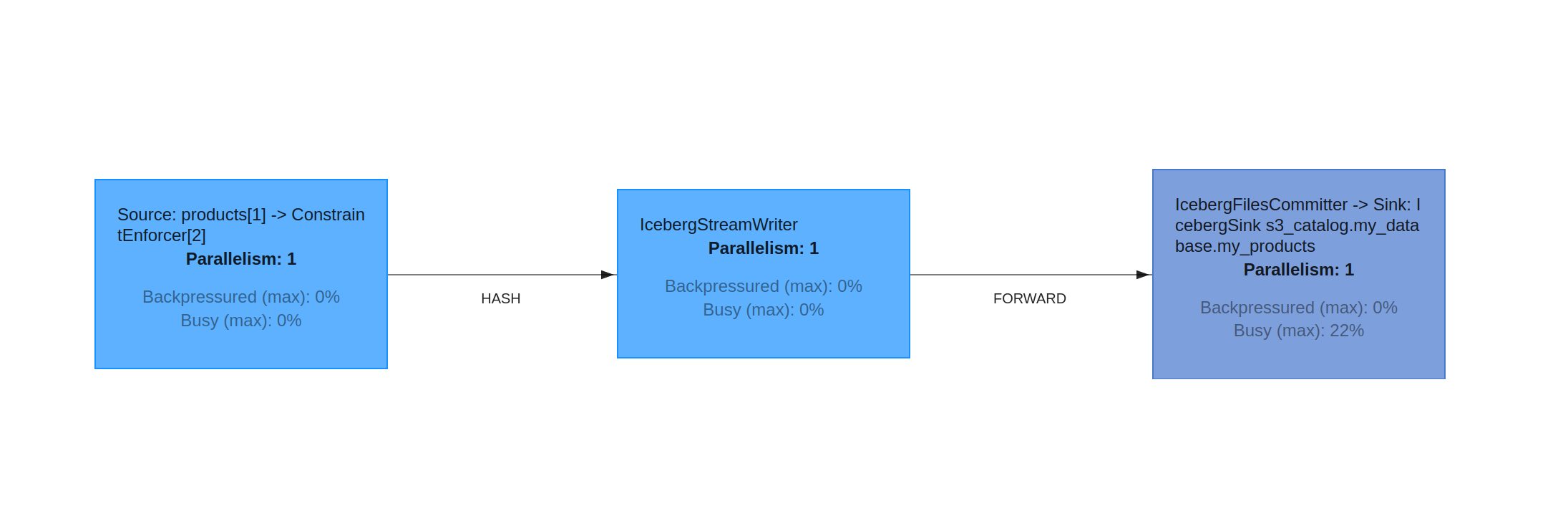
With the data now in s3, I was able to start a new Flink job and query the existing data which is great. Overall, using Iceberg could be a great option for long term storage of data on s3 in a structured format that Flink or other tools like Apache Drill can readily query when needed.
The source to replicate this is on Github at https://github.com/gordonmurray/apache_flink_and_iceberg. The main part to get this running was the SQL command in Flink to create a catalog, nearly identical to the process for Paimon too.
CREATE CATALOG s3_catalog WITH (
'type' = 'iceberg',
'catalog-type' = 'hadoop',
'warehouse' = 's3a://my-test-bucket-gordon/iceberg',
's3a.access-key' = 'xxxxxx',
's3a.secret-key' = 'xxxxx',
'property-version' = '1'
);
After creating a database, a table and sending some data to the table. I was able to start another Flink Job, define the catalog again and query the data on s3 just like I would in a relational database:
use catalog s3_catalog;
use my_database;
select * from my_products;
So all I have to do now if figure out how Iceberg handles schema changes!