Using OpenTofu to create an Apache Flink cluster on AWS
Open Tofu, the open source fork of Terraform™ became generally available last month. I wanted to create a project using Tofu to try it out and see if there were any issues or differences compared to Terraform.
I had a couple of things in mind doing this. Aside from trying Open Tofu for the first time I wanted to make sure Tofu could:
- Use EC2 AMIs created by Hashicorps Packer.
- See if the Ansible provider for Terraform would work with Tofu.
- See if Infracost could still read the HCL and state to estimate cost.
The quick answer is that all 3 continue to work with Tofu. I didn’t experience a single issue.
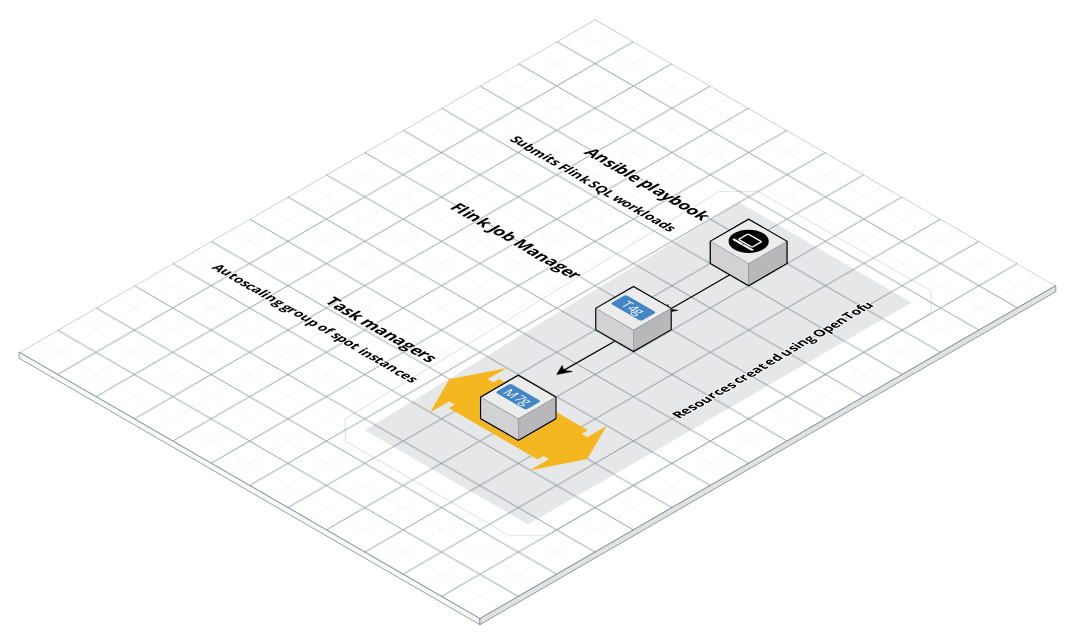
I’m working a lot with Flink right now and enjoying it, so I created a Tofu version of a Flink cluster on AWS: https://github.com/gordonmurray/tofu_aws_apache_flink
Packer
To start off, Packer is used to create an AMI. It is a base instance with Java, Flink and some JARs installed.
Launch templates
Tofu can then use the resulting AMI to create one or more EC2 instancess. For the Flink Job Manager I used a standard aws_instance resource. For the Task Managers I used aws_launch_template launch templates. I used lauch templates instead of directly creating EC2 instances so that any failing Task Manager would be replaced automatically from the base image. Any workloads running on Flink could continue to work uninterupted.
I could use the same approach of using templates for the Job Managers too. That would involve running 2 or 3 Job Managers and so Zookeeper needs to get involved to hold things together. I might add that to the repo in the near future.
Spot instances for Task Managers
Using a launch template opens up the opportunity to use Spot instances. Those are EC2 instances that are lower cost to run. They are lower cost but can disappear at any time. This is where the launch template comes in, it will replace any instance that disappears.
I created 2 independent launch templates and 2 auto scaling groups. Both use spot instances but both have different instance types defined, an m7g.large and an m7g.xlarge. This can help to make sure that at least 1 type of instance is running if the other is unavailable as a Spot instance. It also allows both groups to be scaled up or down independently. One group might better handle sourcing data from Kafka for example and the other might be better suited to sinking data to an s3 bucket.
While using spot instances helps to keep the cost down, it also provides an opportunity to use a larger instance type than one might ordinarily consider using due to being too expensive. Flink loves to use more memory!
User data
User data is a way to run some commands on an EC2 instance when it starts up. Tofu applies the user data to update the Flink config on a task manager as it starts up, such as setting the Job Manager IP address so that a new Task Manager can join the cluster.
Ansible provider
With a Flink cluster up and running the next step is to give it some work to do. Flink can take in work in the form of Java applications compiled as JARs and also in the form of SQL using Flink SQL. I used the Ansible provider for Terraform to get Tofu to call an Ansible playbook to submit Flink SQL work to the cluster.
Using an Ansible provider to submit work to Flink might be an unusual step though it has advantages. Details of resources created by Tofu such as a database, cache or S3 bucket can be passed to Ansible as variables. Ansible can use that information in its Flink SQL jobs.
The Job to submit to Flink is in the form of an Ansible role. A task reads in a template file that contains the Flink SQL and can perform any interpolation needed such as Kafka broker addresses, registry addresses, sink addresses and so on. The directory structure is as follows. More Roles can be added over time to add more work to the Flink cluster
flink_jobs
├── tasks
│ └── main.yml
└── templates
└── queries.sql.j2
3 directories, 2 files
Overall, Tofu worked well out of the box. If felt faster to apply changes compared to Terraform though that’s probably since its a small project.
Some improvements to this project could include:
- Changing the Job Managers to use a launch template also, which introduces a need for Apache Zookeeper
- Have the user data update the config of the instances with different memory settings based on the instance size used.
- For workloads use RocksDB for incremental checkpoints
- Store checkpoints on S3