Query an RDS Snapshot on s3 using Apache Drill
In 2020 AWS announced that RDS snapshots can be exported to s3. The resulting export is in Parquet format which is ideal for searching. “The Parquet format is up to 2x faster to export and consumes up to 6x less storage in Amazon S3, compared to text formats.”
Querying a snapshot directly on s3 can be an excellent alternative to the cost of creating a new RDS instance and in some cases querying the snapshot from s3 can be more desireable than querying a database directly.
To export to s3, go to Snapshots in the RDS section of the AWS console. Highlight the Snapshot and click Actions -> Export to Amazon s3.
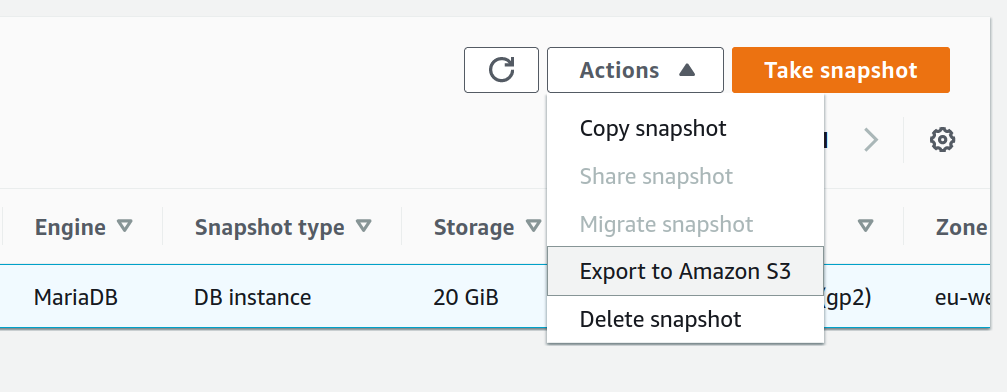
A great feature within this export is that you can either export the entire Snapshot or else a specific schema/table within the snapshot. If you’re in a hurry, exporting a single table to s3 instead of all schemas and tables can be really helpful.
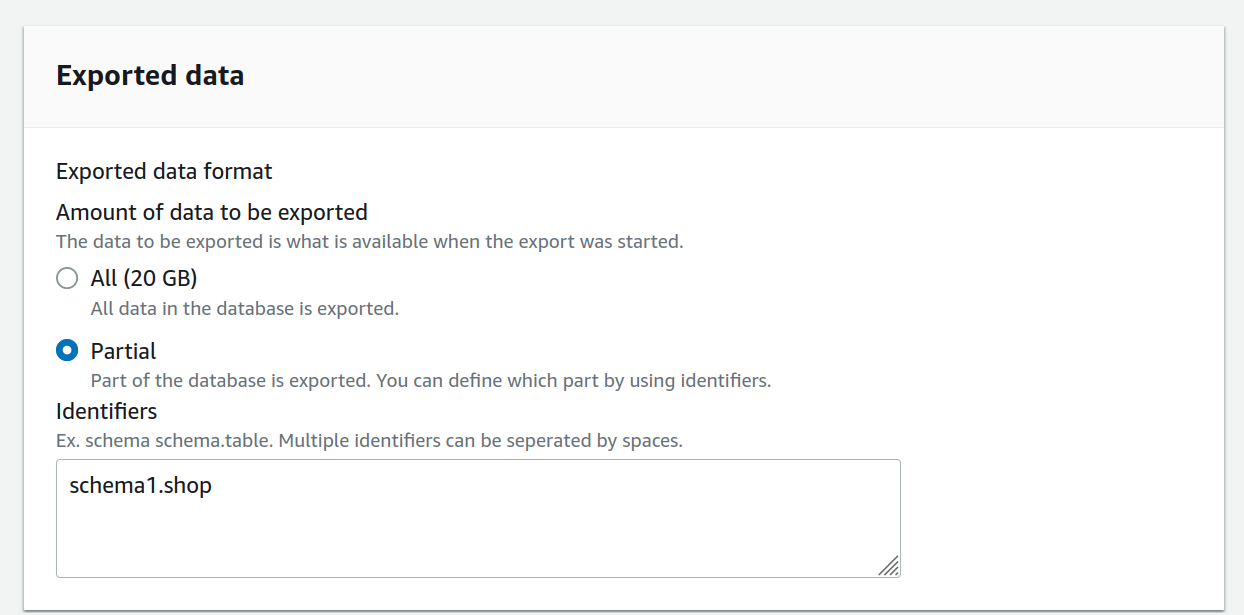
When exporting make sure your s3 bucket is in the same region as the RDS snapshot. You will also need to make sure you have an IAM role with permission to write to s3 and a trust policy in the Role to allow RDS to use the role.
The IAM role trust policy will need to include the following
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "export.rds.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
Once started you’ll see a banner of “The export database-1 is starting.” at the top of the page.
One down side of this is that there is no visible progress of the export. You just have to wait for a “completed successfully” message in the AWS console UI or check the s3 bucket later.
While the snapshot is exporting to s3, the next step is to install Apache Drill. You can get Installation instructions here. If you are using Ubuntu you can use the following to download and run Drill in embedded (standalone) mode:
wget http://apache.mirrors.hoobly.com/drill/drill-1.19.0/apache-drill-1.19.0.tar.gz
sudo apt install default-jre -y
tar -xzf apache-drill-1.19.0.tar.gz
cd apache-drill/bin/
./drill-embedded
Open the Drill UI at http://localhost:8047/
Click the Storage button. Press on ‘Enable’ next to s3.
Click on Update next to s3 and add your s3 bucket name, IAM key and secret so that Drill can query s3.
To make sure Drill is connecting to s3, you can query it using:
show schemas; # show any schemas set up from the Storage section
use s3.root; # Use the s3 Storage
show files; # Show and folders/files in the s3 bucket
You should see any files or folders in the s3 bucket. You can look in sub folders as follows:
show files in PATH/TO/SNAPSHOTS;
To start querying your data, you can use more or less regular SQL queries. Querying a specific file or a collection of files:
select * from s3.root.`folder/filename.parquet` limit 10;
or
select * from s3.root.`folder/` limit 10;
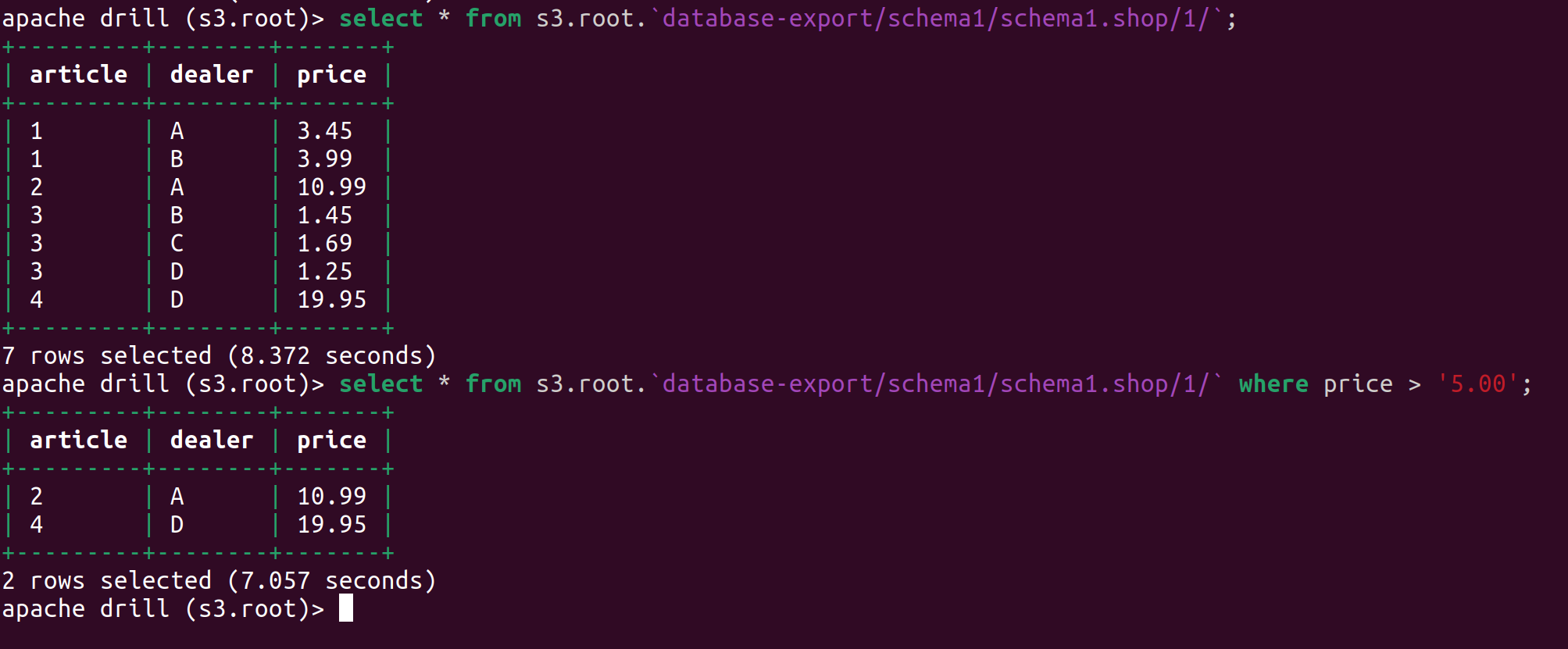
Query results are quick and you don’t need to configure Apache Drill to inform it about your data structure before you start running queries.